What is a high-level test?
To get it out of the way, there are multiple types of high-level tests. You might have heard names like functional, acceptance, end-to-end, and more. The distinction might be important to a particular team, but it’s not relevant to this article, so I won’t focus on their differences. The common thing between them is that they are approaching a larger system as a whole, and in particular, I will be using an HTTP API as an example, and my testing surface will be the request/response level. What’s also very important is that I won’t be doing a full end-to-end test, since parts of it I will want to replace with test doubles.
In principle, these tests aren’t that different from unit tests. That might feel controversial, but bear with me. I described the system under unit test in the following way:
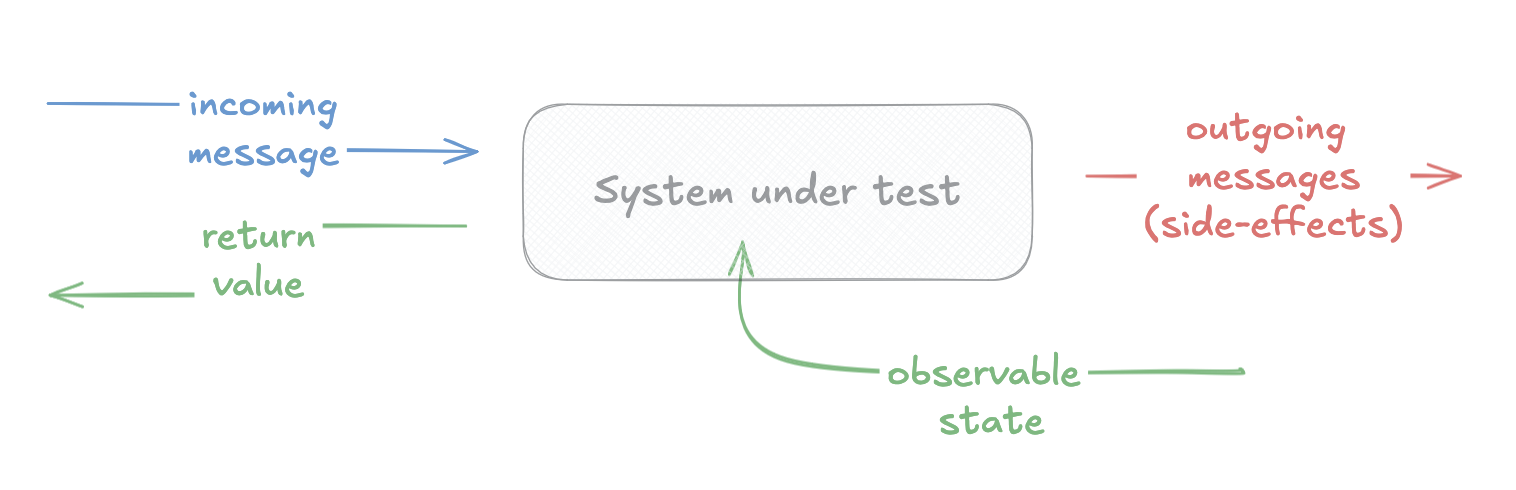
That looks similar when we treat our HTTP API Application as a black-box. Let me fill in more specific names on this same diagram:
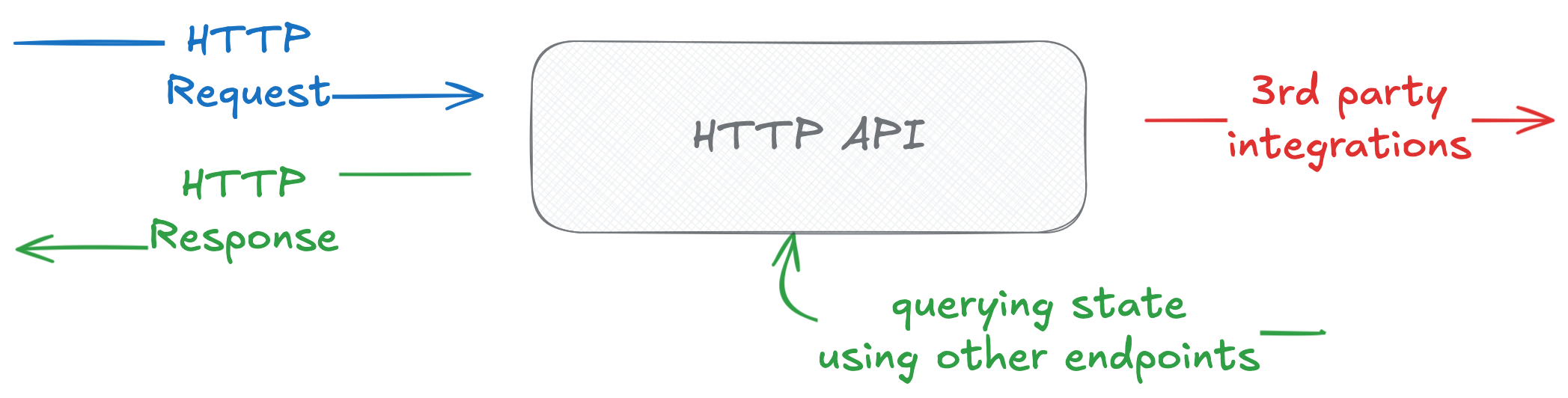
The public-facing interface of the app is an HTTP endpoint taking a request and returning a response. After changing state, for example, by creating a record, we may query the list endpoint for the same record type to verify the expected side effects (in other words, we check if the record was created). On top of that, there might be other side effects which are not as directly observed — when the app needs to communicate with a 3rd party, calling an API, sending an email, putting a message on a broker, or others.
The model is the same, but the black-box under testing is larger.
How to deal with a larger black-box?
This is the most crucial distinction, in my opinion. For unit tests, usually there are fewer dependencies, the context it operates on is smaller, inputs and outputs tend to be simpler, and the number of possible expected side-effects is more limited. For an HTTP API, the background context is really vast. Actually, it’s your entire application. The input/output layer is vague — it’s just an HTTP request, which seems simple — it’s just a set of headers and a request body, but that simple format can represent enormously complex scenarios. Your use cases will also probably consist of more than a single call to be meaningfull.
This means that for a better developer experience, we need to put more effort into handling these inputs and outputs, as well as have more advanced methods of controlling the context. That’s a topic for a separate article, but I’ll just tease that it’s best to create a whole separate testing SDKs for your app, a separate one for each of the actors interacting with your application. That might be an AdminSdk, an AuthenticatedUserSdk, but also ChargebeeWebhookSdk, or CronSdk, or MessageBrokerSdk. These represent different actors or agents interacting with your app, and encapsulate common behaviour (for example: the webhook SDK will automatically sign requests, so you don’t need to be bothered by it in your test case). We will use those to improve the readability and reuse of our test. Similarly, instead of making direct assertions on the HTTP response bodies or headers, it’s useful to wrap them in a dedicated assertion classes to add semantic meaning, better messages, and hide away the complexity in the tests.
I’m not inventing an entirely new concept here. In the world of e2e testing, a similar pattern is commonly known as the Page Object Model.
You can explore WonderNetwork/slim-kernel-testing-harness as a library implementing these concepts.
Chargebee case study
Let’s see a practical example on how to test a real application, with some legacy problems, suboptimal architectural decisions, and a 3rd party API integration. This is based on a real modernization of a Chargebee integration I was recently performing. The app was using the chargebee/chargebee-php:^3 package, and because some orchestration around how it was used was changing, I wanted to add automated tests to have more confidence that the expected behaviour did not change.
One of the use cases was quite simple:
when a user changed their company name in the account panel, the change should be reflected in their Chargebee customer
The left part of the diagram — input/output — is quite simple. I already had a use case facade for the company administrators, which handled the authentication and exposed simple methods to call the different endpoints. I simply added another one to call the PATCH endpoint to change the company name, and an assertion to test that the response is successful and contains the new value. Simplified, this could look something like this:
function changeCompanyName(string $name): void {
$response = PatchCompanyEndpointAssertion::of(
$this->httpClient->patch('/api/company', ['name' => $name]),
);
$response->assertSuccessful();
$response->assertName($name);
}
The right part of the diagram is trickier
The left side was easy. I can even add another check to verify the observable state, and check that the new name was persisted in the database, by querying a GET endpoint for the company. But there are also expectations about outgoing messages: side-effects made on the Chargebee API. When writing a unit test, we would use the spy pattern to check these.
How to inject a spy into an entire application? Well, your framework usually affords methods to provide customized configuration for tests, or even mock some of the dependencies at runtime, so that’s not a problem.
Unfortunately, the default way of configuring and using Chargebee in the v3 SDK is by registering a static, global Environment instance. This allows you to then call different endpoints all across your codebase, without using dependency injection. And this was the case for my application as well.
The next best thing would be to replace the HTTP client used by the SDK and provide a mock handler, but the package hardcoded the calls and didn’t expose a way of doing that either.
To start, this is how my app looked from a helicopter view:
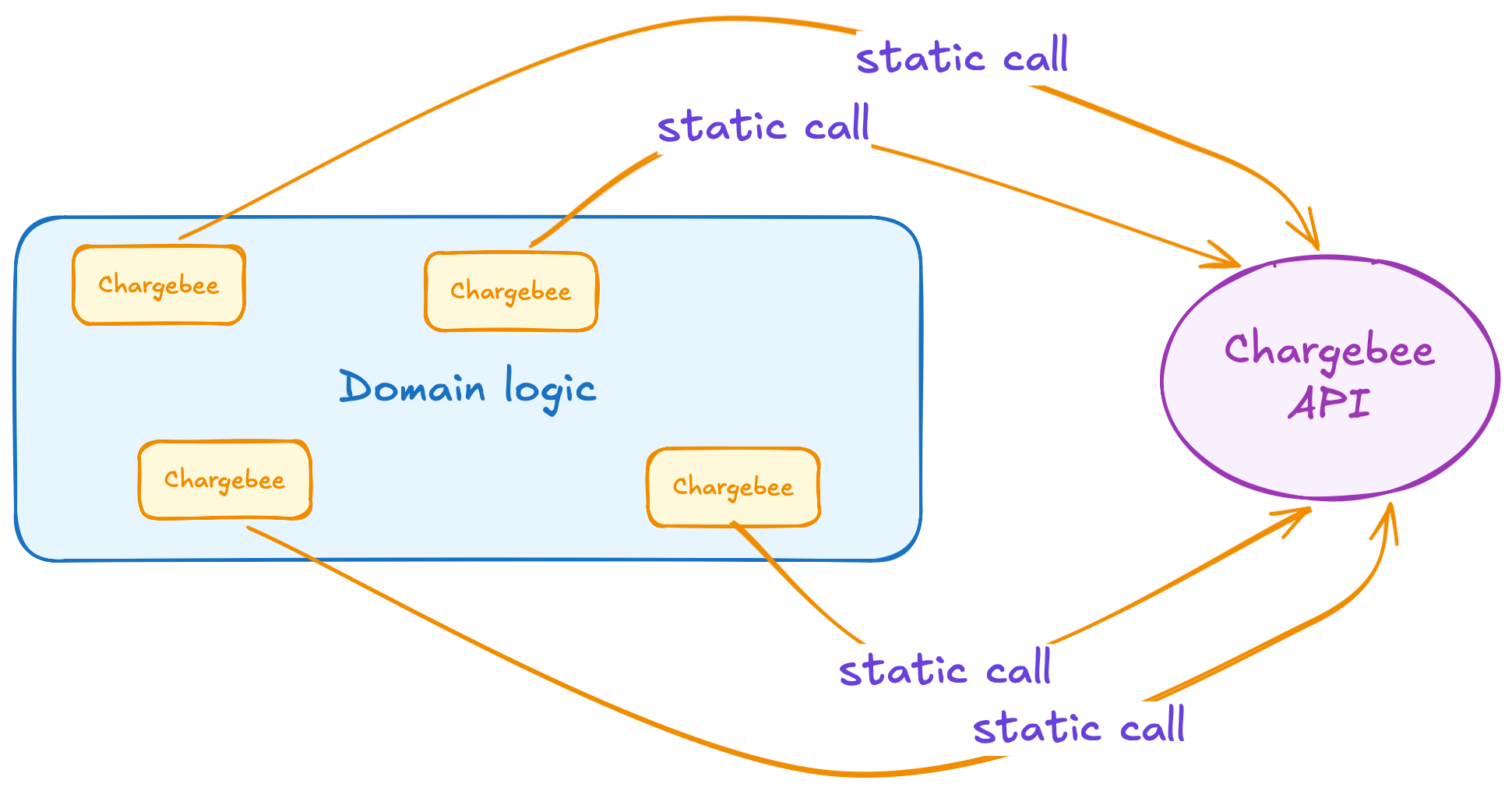
Isolate all calls to a single facade
There was no practical way of replacing the Chargebee integration with a test double. The first order of business was to improve that situation. Instead of making these calls ad hoc in any class, the goal was to move all the uses of Chargebee endpoints to a single facade, which then could be replaced with a test double.
There was a lot of moving around, and along the way, I needed to separate any business logic around those calls. The goal is to replace that facade in tests, so I wanted as little business logic to be mocked, and preferably only the Chargebee integration.
The final result looked something like this:
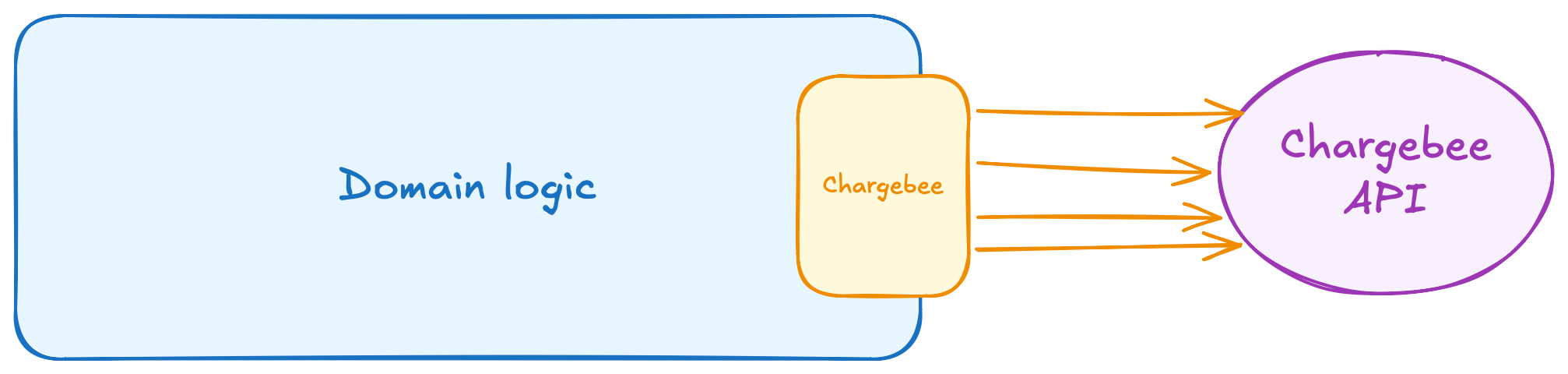
All the calls are grouped in one place. I specifically placed it on the edge of the domain area, because it’s a port — a window our application can explicitly use to communicate with the outside world. And through that window, we can pass in different adapters. It will be a Chargebee API client for production, but an in-memory test double for our high-level test:
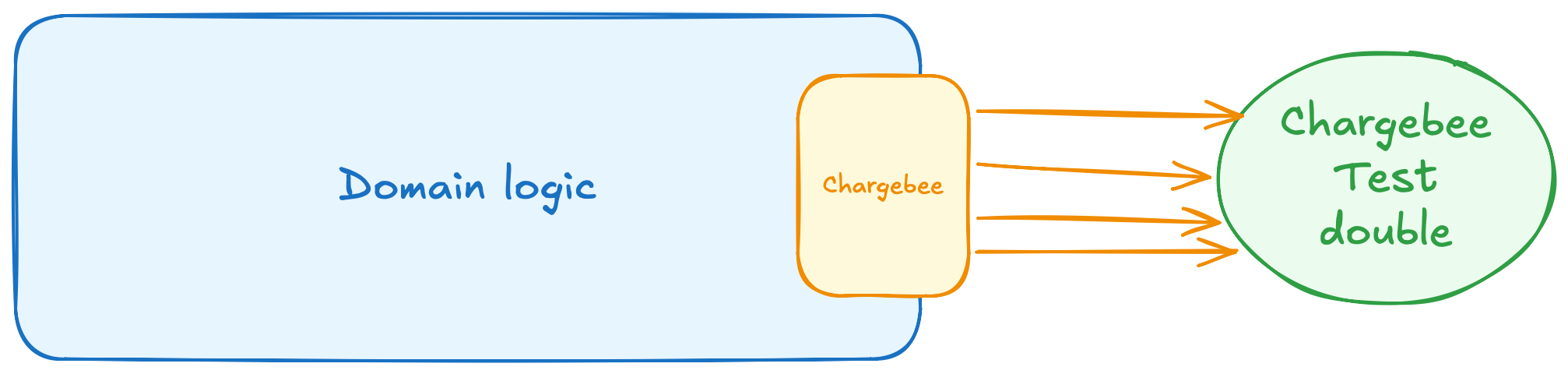
Implementing the test double
The previous efforts allowed me to finally replace a single dependency in my test environment to mock all the communication with Chargebee. This isn’t a simple task, because not only are there many methods exposed on that facade (both the actual API and the test double split their responsibility into many different classes), but we also need to accurately simulate the real API behaviour and state changes. The better we do it, the more reliable our test will become.
As an example, for our company name change use case, here’s a partial implementation that would allow us to finish the test:
final class ChargebeeCustomerEndpointTestDouble {
private array $customers = [];
public function givenCustomerExists(Customer $customer): void {
$this->customers[$customer->id] = $customer;
}
public function updateCustomer(CustomerId $id, CustomerChangePayload $change): void {
$this->customers[$id->value] = $this->get($id)->withName($change->name);
}
public function get(CustomerId $id): Customer {
return $this->customers[$id->value] ?? throw new CustomerNotFoundException();
}
}
The first method is an internal one used only in tests. It allows us to short-circuit our scenario and start it in a hypothetical situation where the customer already exists, instead of going through all the steps from the start. A different team might very well choose not to use shortcuts and simulate the entire journey, starting with a blank slate.
The following two methods are used by the facade, or maybe they are even part of the interface, i.e., they are called by our domain code. They are responsible for recreating the same logic that happens when we call the Chargebee API. In an advanced use case, this would be more complicated: for example, it would allow you to simulate exceptional conditions, errors, missing data, etc.
Putting that test double into the test container, our test case can be completed.
#[Test]
function companyNameChangeIsReflectedInChargebee(): void {
// given we set up the pre-existing context:
$companyScenario = $this->companyUseCase->givenCompanyExists("Evil Corp");
$this->chargebeeUseCase->givenCustomerExists(
new Customer(
id: $companyScenario->companyId,
name: "Evil Corp",
),
);
// when the API is called
$companyScenario->changeCompanyName("Acme");
// then expect the side-effect was produced by inspecting our test double
$actual = $this->chargebeeUseCase->getCustomer($customer->companyId);
self::assertSame("Acme", $actual->name);
}
Testing one last assumption
The test case shows that given some context (customer exists), when an input is applied (HTTP request to the correct API endpoint), a response is produced, and some state change can be observed (response from a separate endpoint), and a side-effect was produced on a Chargebee port. But I explicitly excluded the real implementation of the 3rd party integration from this scenario. I can be confident that 95% of the code works, but I have no idea if the last part is correct.
Let’s flip the scenario and test the SDK itself. Remember, it didn’t allow us to provide a test double for the HTTP client, so we’ll resort to using a real API. Well, kind of. WireMock is great at pretending to be the real thing. It allows us to register a set of mappings — a collection of endpoints and a list of conditions to match a request — and associate them with predefined responses. For all intents and purposes, we can make WireMock behave exactly the same as the Chargebee API for the inputs we give it.
By placing a capturing proxy in front of my application, I was able to methodically collect all the real requests and responses the system makes to the Chargebee API, and use them in an integration test of the SDK I implemented, cementing its behaviour.
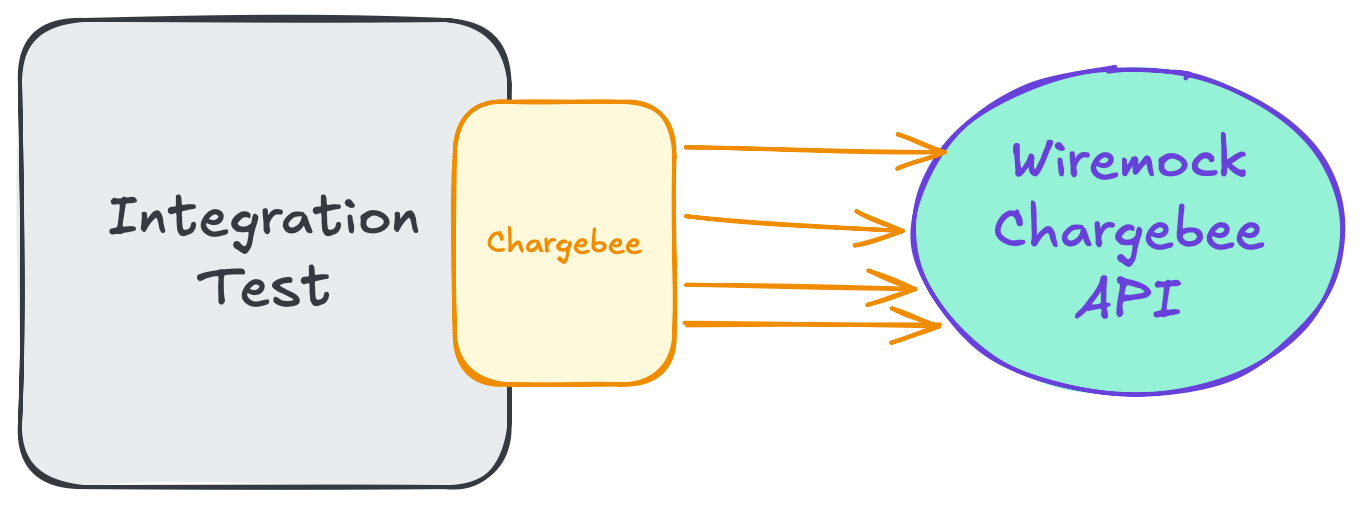
With this pair of tests:
- One high-level, using a Chargebee Test Double, covering 95% of the application’s „area”
- And a second one on a lower level, targeting just a single unit and a very fast mock API
We have covered the entirety of the code paths required for our feature.
Final bonus
After all of the above was done, and I could be pretty certain my application works as intended, I moved one step further. I upgraded the deprecated version 3 of the Chargebee SDK package. At this point, it was fairly easy because of the following facts:
- All usages of the
ChargeBee\namespace was limited to my one facade, so I knew all the changes would be contained to that one place (yes, I mapped all of the inputs and outputs of my facade to my own value objects). - The new package version had some implementation changes, but it still used the same API, so I knew the inputs and outputs were the same, and the HTTP calls were also unchanged.
After I reimplemented the facade (Chargebee v4 is quite a breaking change, as it fundamentally changes the architecture of the SDK), I was able to rerun the integration test, expecting it to pass with flying colors. After fixing two mistyped parameters, I confirmed exactly that: the documented behaviours were exactly the same when using the v4 implementation, and I could safely merge that change too.
Closing thoughts
As you were able to see, a high-level test doesn’t need to be that different from a unit test. There is more boilerplate to keep it manageable, and to hide away the complexity and area of the affected context, but in the end, the test case follows the same principles:
- Arrange (prepare a bunch of stuff), Act (execute our scenario), Assert (check for its effects)
- We check responses, we check observable state change, and we check side-effects produced on the outside of our black-box, but we never need to look inside it
If you haven’t already, you can read more of my articles about testing, including some other case studies, or a detailed chapter focusing on unit tests. And if you need that kind of support, find out how I can help your project.
]]>











