This chapter concludes this 4-part series, including some juicy technical bits:
- Leaving Phone
- Changing teams
- Switching the tech stack
- Learning NestJS 👈
I love greenfield projects, but I hate the bootstrapping phase. Despite working almost exclusively on new projects since 2015, I rarely actually need to start from scratch. Up to this point, it usually meant copying bits and pieces from previous projects.
This was not an option this time, since, erm, the stack changed. So I started reading and talking to the team a lot to taxi my way up to some basic proficiency in the NestJS framework.
In the first days, each step forward raised dozens of questions, obstacles and unknowns. Imagine you’re hungry and need some eggs. But instead of just grabbing a wallet and going to the corner store, you realize that you have no legs, but that’s not really a problem, because money wasn’t invented yet, so you need to grow some chickens instead. And then it turns out they don’t have type definitions, so you can’t use them.
Focus area
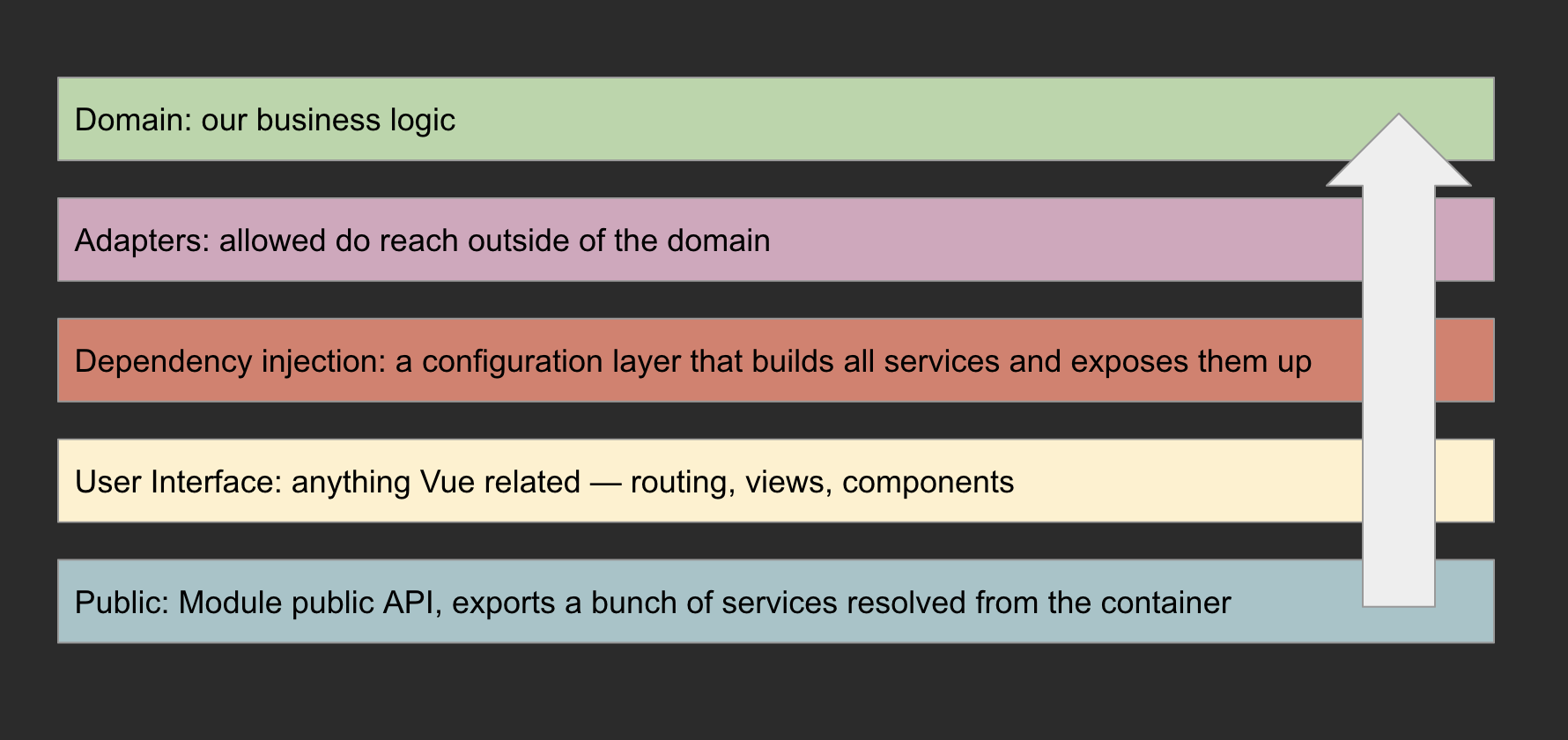
Let’s start with some fundamentals: what I am trying to achieve here. The main goal is to have a semi-decent NestJS application. Both I and others on the team adapt domain driven design, so I’ll use those principles in this codebase too. Testing is an important factor too: it helps to develop with higher confidence, and actually improves my developer experience, since the app is headless, so it has no real interface I can poke around.
There are also other concepts that seemed important to me from the get-go, and those include:
- Dependency injection container and the way it’s configured
- Asynchronous messaging using queues
- App configuration, including environment variables — from experience, it’s always a mess
- Serialization and validation. I hoped for a mature framework that would help me to limit the boilerplate associated with DTOs
- Last but not least: the ORM.
So let’s dive right in to see the steps I took along the way to complete the first phase of building my application: the passing of a simple end-to-end scenario.
Dependency injection
I think this is one of the core parts of any framework. In fact, I’ve seen micro frameworks which were nothing but a DI container. In Nest, the DI is engraved deep into the system, so that is not unexpected. But it is also tied closely to the module system, which raises an eyebrow for me. I’ll touch on that later.
Due to the way how JavaScript and/or TypeScript work, there are a lot of shortcomings all JS DI containers share: you can’t use the interface as an identifier and thus you need to explicitly tie class dependencies to DI tokens. In fact, autowiring mostly doesn’t work and you have to resort to juggling manually registering classes and their dependencies and slapping @Injectable() and @Inject() all over the place. A skill I’m yet to master.
The autowiring part was actually a hard blow for me. After being skeptical about it at first, when I was still developing with Symfony, I reached a point where I mostly only used DIC configuration to wire value objects containing configuration — the rest was either autowired, or used dedicated factories.
Unfortunately, until a popular TypeScript library starts to pre-compile the container configuration in build-time (if that is even technically possible) there is no getting around it.
Customizing the DIC for tests
I like to treat the app like a black box during end-to-end testing. To achieve that, I need to recognize all inputs and outputs. Among them are for example HTTP adapters, or any adapter that reaches the outside world for that matter. It’s the benefit of the hexagonal architecture that I know exactly where to look for them. Entity persistence adapters in particular do not match that definition, since the database is part of the app during tests.
So I know there is a group of services that I want to replace with test doubles during e2e, because I want to run put my black box in a controlled environment. I want to switch them at the same place they are defined in the main container, so the definitions are close together (it’s a design choice). „The Nest way” is rather to instantiate individual modules, and mock certain services in each test case explicitly, or use some other form of jiggery-pokery. I haven’t decided if I want to cut my box into pieces (by pulling out individual modules), so for the time being I’ll stick with what I know.
To achieve my goal, I created a function that will register either the regular adapter or the test double. The way it works is that for each InjectionToken it registers both versions of the service on the side, and then uses a factory method to return the correct one depending on the runtime config.
Modules
Let’s get back to the modules. It’s the framework’s opinionated method of splitting the app into smaller parts and managing dependencies between them. They are strongly encouraged. And while I believe it’s convenient to have your dependency container configuration assembled from pieces, I think the job of separating concerns can be done in a better way.
This is why I said fuck it and opted for dependency cruiser instead. Shout out to Lech who reminded me about deptrac (a PHP alternative) and triggered me to start using it back in the day. You see, having a bunch of hierarchical parts of the DIC that are private by default (I’m talking about Nest modules) does not actually prevent you from doing anything, it just inconveniences you to do so. There is nothing stopping you from actually importing any other module all over the place, exporting everything, and doing a lot of mess in the process.
Dep cruiser on the other hand sets out strict rules about what can depend on what. And it’s not on the DIC level, but on the file level, so it applies to any kind of imports. You can set your layered architecture, you can raise module boundaries, and take them down by exposing internal APIs.
I’m not yet actively going against the framework yet, but I’m kinda skimming on the surface.
Testing
I think I can have a high unit coverage, because of the way I write code that is easy to test, and how fluent I am with unit tests. They just come naturally to me. So the first thing I did was to move the testing sources to __tests__ subdirectories, instead of just suffixing the names with .(test|spec).ts. That is because I create a lot of various test doubles, and they wouldn’t have a place to live otherwise. On top of that, dep cruiser forbids any application code to depend on anything isolated to the __tests__ directory, so there is an added benefit of not using any of them in production.
I have nothing against jest mocking capabilities, but having explicit test doubles improves readability, increases reuse, not to mention that they are first class citizens. You can inject them into the container (as mentioned earlier), they are affected by automatic refactorings done by the IDE, etc. I’ll surely also resort to jest mocks to cut some corners.
Another thing that I immediately started using are Mothers. Quick googling hasn’t yielded any interesting results as to dive deeper into that topic, so I will leave this as an exercise for the reader. I’ll just quickly summarize:
A Mother is a static factory containing convenience methods for creating entities. I used to write code with dozens of places where new Entity was used, mostly in test sources, and any changes to the entity’s constructor were a pain. With the help of Mothers, you move those calls to one place. It also abstracts away the creation process (it’s a factory after all) making the test sources more readable and more descriptive (e.g. OfferMother::deactivatedLastMonth()).
I think it was Patryk who introduced me to this pattern, and I must admit, I wasn’t a fan at first, but the concept grew on me as I was writting more tests.
End-to-end testing
I wanted to adopt the gherkin syntax for jest unit tests because it’s so descriptive and powerful. It has done wonders for us at Phone. I even started installing the jest-cucumber plugin but it felt quite poor. What else should I expect from an npm package? And then I realized that I should just use cucumber-js directly.
The setup was straightforward, my IDE supports the feature files natively and offers completion, and suggests implementing missing step definitions, allows me to run individual scenarios. It also enables me to debug them, although I needed to work around the step timeouts, which were eager to end test cases prematurely.
One thing I miss is that the step definitions are not a part of the Nest application, so I can’t use the DIC to provide their dependencies. Instead, the steps have the service locator injected and fetch whatever they need explicitly. I can live with that.
Object-relational mapping
The first thing I was told: Prisma is shit. Don’t use Prisma. Run away. Thanks for the tip! I’ll use TypeORM instead. That’s a name I’ve heard before, and it’s officially supported by the framework. Nothing can go wrong.
Oh, but you can’t use your domain entities, you have to map do persistence DTOs — was the second thing I was told. Damn, no, please no. I might as well use ActiveRecord instead. That was a real bummer.
Fortunately, there is a somewhat hidden, not well-documented option called entitySkipConstructor that basically allows me to skip the mapping step. Maybe some DDD evangelists will fume about it, but that’s the boilerplate I would very much like to avoid. And that is something I am used to (PHP’s Doctrine was doing just fine in a similar role), and some familiarity at this point brings me much comfort.
After finding another poorly documented feature I learned that I can decouple my entity classes from their mappings. In other words, instead of using decorators, I can define the same metadata in a separate place. Great, that keeps my domain a little cleaner. I didn’t read the fine print which stated that I am restricted in the way I can name my schemas, but that wasn’t anything a couple of hours of debugging wasn’t able to fix.
The framework is kind enough to provide me with decorators to reduce the boilerplate of injecting repositories, but at the same time forces me to add the boilerplate to configure which schemas are allowed. The module thingy gets in the way again. Is there a way to export everything by default? I’ll set global to true, just in case.
On the upside, the framework can automatically synchronize the database schema in a test environment. That’s something that had caused a lot of problems for me in the past, so I’m glad it’s available out of the box here.
No affixes
Don’t get me started. I don’t need to know if something is an interface or an implementation when I depend on it. Either one is a contract, and it can change its nature freely without affecting the consumers. This is why I don’t prefix with I and I don’t suffix with Interface.
Service suffix feels even worse. It reeks of the times when logic was contained in controllers, and sometimes extracted to those special things called „services” (if you had a DIC) or „helpers” (if you didn’t or used functions). A class does not concern itself with whether it is or isn’t a service, and it should be left out of its name.
In addition, Nest’s conventions add a lot of .service, .controller, .port, .adapter and other weird stuff to otherwise fine filenames. I have no idea why I would want to do that. I always followed a simple rule: the file is named identically to the thing that lives inside it (that also implies one declaration per file), which was actually forced by PHP’s autoloading standards. And my IDE understands that when I’m renaming stuff. I like that rule.
I think I’m openly going against the framework conventions here, but it’s a hill I’m willing to die on, especially since I was such a vocal proponent of suffixing in the past. I’m reformed. I only keep the suffixes for unit tests, since they don’t contain any single named thing inside, so I use the SUT.spec.ts format for jest to have an easier time finding them.
Zod
I’ve heard this name thrown a lot on reddit, but I never had the chance to use it. I wasn’t expecting much. In fact, I was rather looking for an assertion library for two reasons, one more important than the other:
- I wanted it for domain assertions in production code, and
jest was only a dev dependency
- My IDE didn’t auto-import the
expect function in cucumber step definitions, thinking it was in jest context and that it’s not required
But I stumbled on Zod instead and OMG it is so game-changing. Is there a thing it cannot do?
- Validating configuration files, including environment variables
- Defining outputs from APIs I’m using, validating, and transforming them to a more friendly representation at the same time
- Oh, it can do for your NestJS API inputs as well, fancy!
- The gherkin table inputs I used to write custom transformers by hand (in Behat) are now as simple as
()
And all the time it infers the output type, so TypeScript is aware of what comes out of my JSON.parse(): any mess after I pass it through schema.parse(). The need to have any kind of input DTOs, their decorators for validation, transformers to meticulously fill out each field, the validators themselves, and mappers to match input format to something more familiar — they are all gone.
Would recommend, 10/10, even without rice.
Summing up
It was a tiresome journey for me. A one that I didn’t know where would lead me or how long it would last. Finally I think I have a quite good grasp on it, and I will be feeling more comfortable going forward.
Imagine my joy seeing the test scenario turn green!
]]>

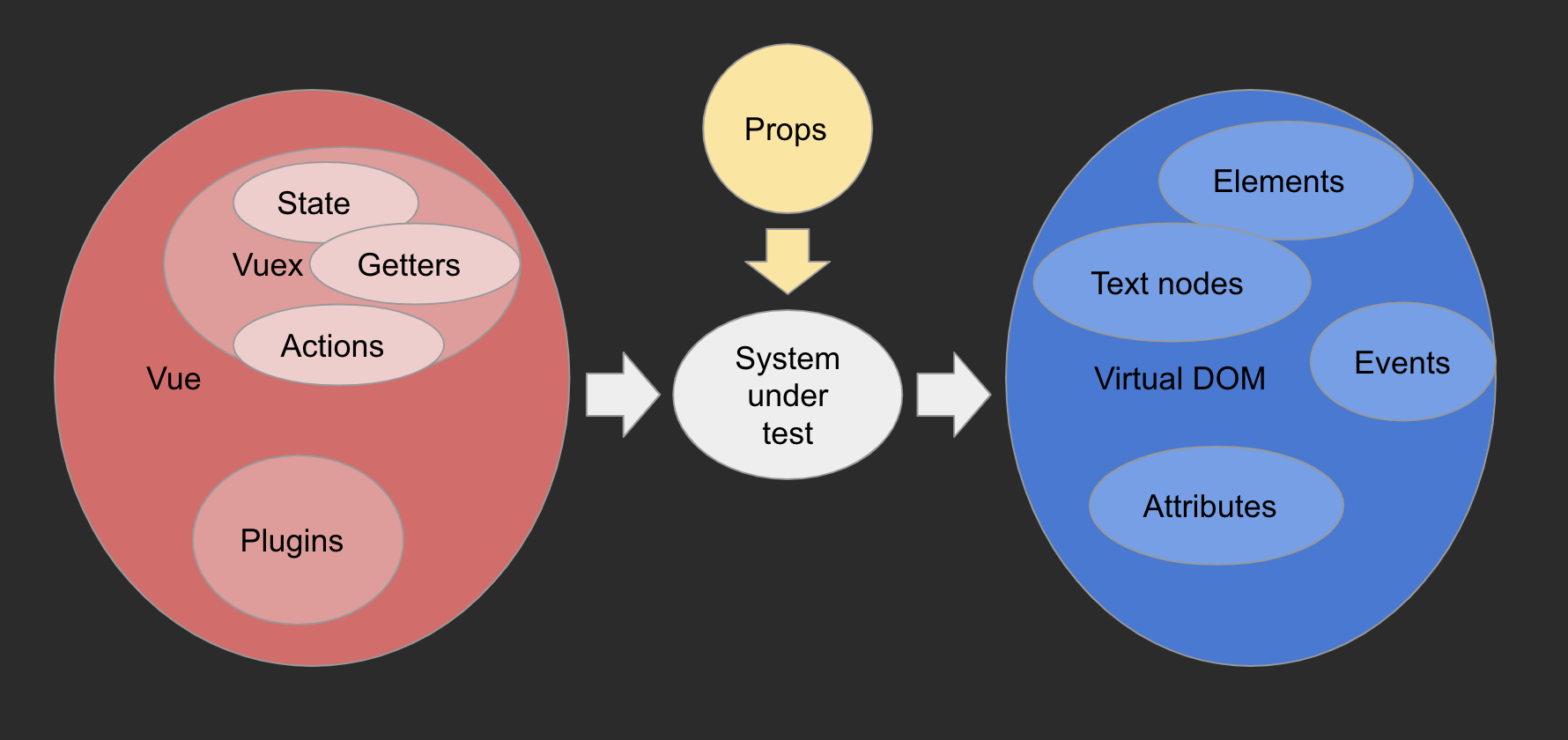 Large testing surface
Large testing surface
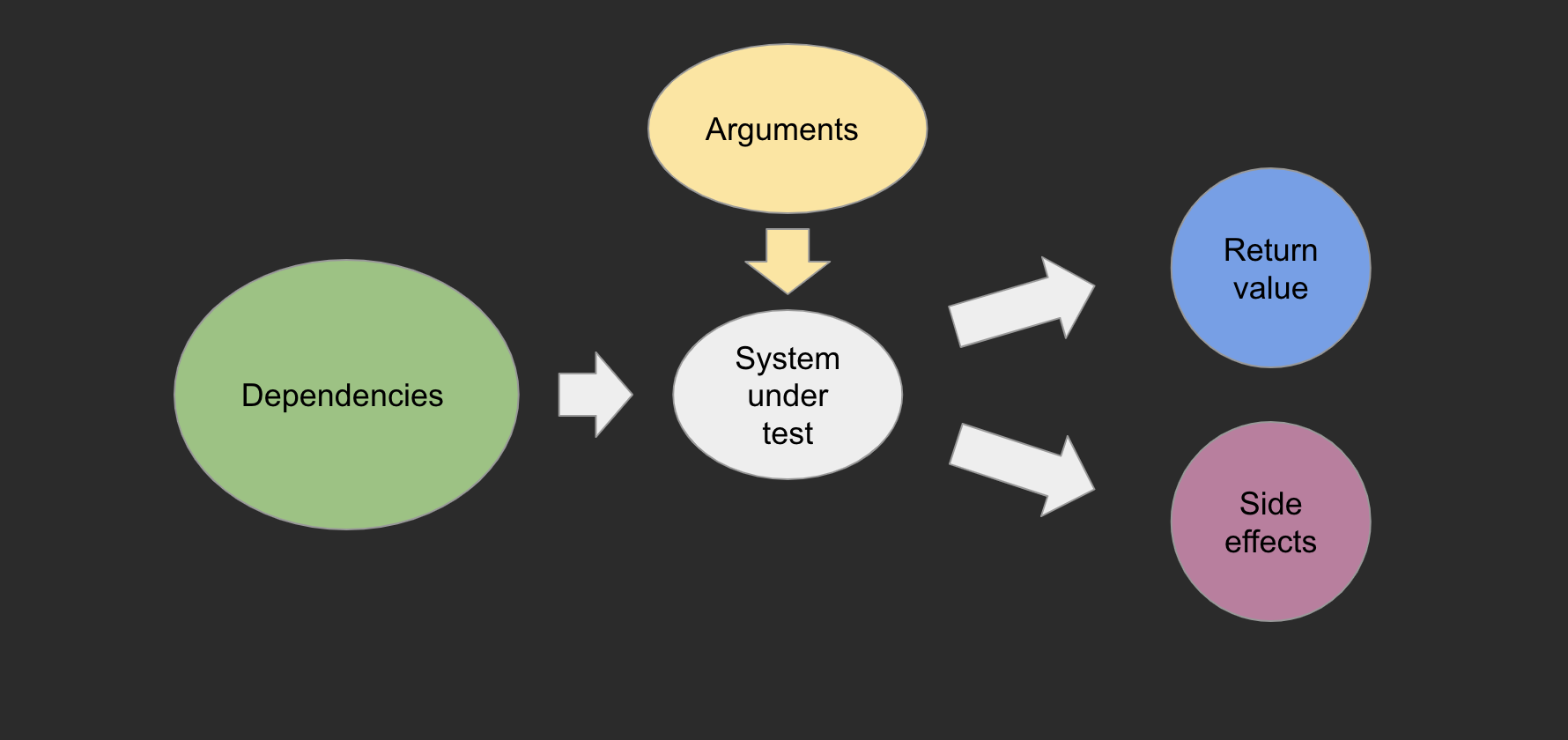 Small testing surface
Small testing surface